
Parameter-Efficient Fine-Tuning or PEFT is a more efficient approach to adapting large language models (LLMs) compared to traditional full fine-tuning. Instead of modifying the entire model, PEFT focuses on fine-tuning only a small subset of the model’s parameters, making it less resource-intensive. This allows for faster adaptation to specific tasks while maintaining most of the pre-trained knowledge of the model, offering a cost-effective solution for improving performance on specialized tasks.
This is Part 4 of my series in LLM Customization. In this post, we will take a look at PEFT. It is an umbrella term for methods that allow fine-tuning of models with fewer parameters, making the process more efficient and less resource-intensive. Instead of updating all parameters in the model, PEFT methods focus on adjusting only a subset of parameters, which reduces the computational cost. Common techniques include:
- Prefix tuning – Optimizes additional input tokens rather than modifying model weights.
- Adapters – Small, trainable modules added between model layers.
- Low-Rank Adaptation (LoRA) – Adds low-rank matrices to fine-tune a model with minimal computational overhead.
In this post, we will focus on LoRA.
Low-Rank Adaptation
LoRA freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times. LoRA performs on-par or better than fine-tuning in model quality (Hu, et al.).
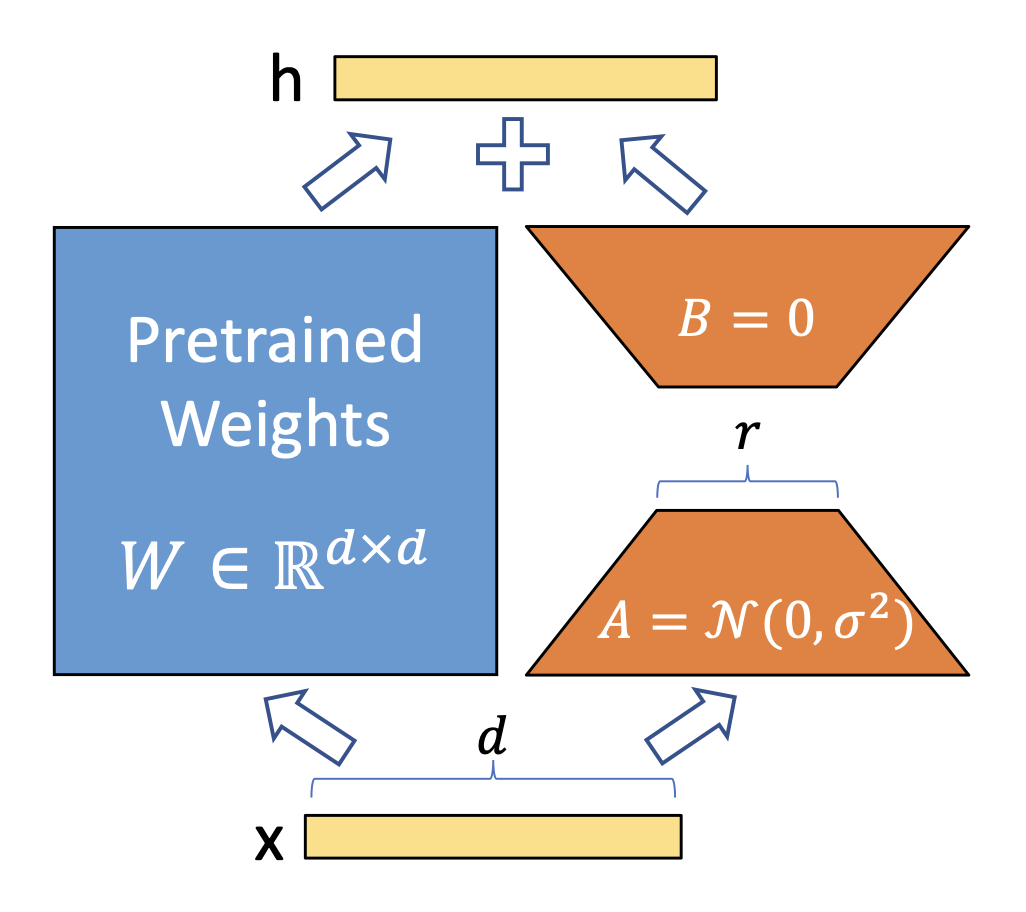
This is illustrated by the diagram from Hu et al. Here, x is the input vector. In a typical model, it would pass through the pretrained weights W to produce the output h. With LoRA, instead of modifying W directly, two small trainable low-rank matrices A and B are injected. The input x passes through these matrices to compute an additive update to the output. These matrices are the ones updated during LoRA training—not W, as would be the case in full fine-tuning. This update is then added to the original output, influencing h. The original weights W are frozen or not modified.
Process
- Prepare fine-tuning dataset. This is labeled, domain- or task-specific, and normally smaller than full training/re-training.
- Prepare base model.
- Integrate LoRA layers or adapters into the base model.
- Train the layers/adapters. Like other deep-learning models this involves cost functions, back propagation, and evaluation.
- Test the performance of the LLM with the test data.
Compared to full fine-tuning, this has lower cost, faster training, and reduces the risk of overfitting.
Components
Torch
Underneath all these is Torch. When using torch in Python, it usually refers to PyTorch. The original Torch was a deep learning framework written in Lua, and PyTorch is considered its spiritual successor. Built in Python—hence the name Py-Torch—it serves as a powerful framework for building, training, and deploying neural networks, powering the entire machine learning and model training pipeline.
Hugging Face
Hugging Face is a company that’s become the go-to hub for machine learning models and tools, especially in natural language processing (NLP). They develop and maintain open-source libraries that we will be using:
- datasets – The datasets library gives you access to thousands of ready-to-use datasets — NLP, audio, vision, and more. This includes the Alpaca Dataset.
- transformers – The transformers library provides access to thousands of pretrained models for NLP, computer vision, and more. This includes the TinyLlama Model.
- peft – The peft library provides a framework and tools for applying PEFT techniques to LLMs including prefix tuning, adapter, and of course LoRa.
Alpaca Dataset
The Alpaca Dataset is a high-quality dataset specifically designed for fine-tuning language models on instruction-following tasks. It was created by researchers at Stanford to provide a good resource for training models to better understand and respond to natural language instructions, mimicking the style of instruction-based tasks that are prevalent in models like OpenAI’s GPT series. It was used to fine-tune Meta’s Llama 7B Model to create the Alpaca Model. We will be using the same approach but via PEFT and, due to resource constraints, with a smaller subset. We will not get significant changes but the approach is what we’re after.
TinyLlama
TinyLlama is a small and efficient open-source large language model based on Meta’s original LLaMA (Large Language Model Meta AI) architecture. It was developed to provide high-quality performance while being lightweight enough to run on consumer-grade hardware. Despite its name, it is actually a capable 1.1 billion parameter model. We will be using TinyLlama/TinyLlama-1.1B-Chat-v1.0 a chat-optimized version, tuned for conversational tasks. But ChatGPT it is not. Which is why we will fine-tune it as an exercise.
Quantization
Also due to resource contraints, we will be using quantization during training. Quantization is the process of converting a model’s weights from high-precision floating point numbers (usually 32-bit floats) to lower-precision formats like 8-bit integers (int8) or 16-bit floats (float16 or bfloat16). This will save us on memory requirements.
Install Packages
First, we install all the necessary packages:
pip install torch transformers datasets peft bitsandbytesInference With Base Model
To set the baseline, we first try inferencing with the original/base model.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
# Load tokenizer and model without quantization
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # required for training
# Choose device manually
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load base model on the selected device
model = AutoModelForCausalLM.from_pretrained(model_name)
model.to(device)
model.eval()
# Generate function
def generate(model, prompt):
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=1024, do_sample=True, temperature=0.7)
return tokenizer.decode(output[0], skip_special_tokens=True)
# Alpaca-style instruction prompt
prompt = """### Instruction:
Explain the difference between renewable and non-renewable energy sources.
### Response:
"""
print("=== BEFORE PEFT Fine-Tuning ===")
print(generate(model, prompt))PEFT Training
Next we run, the PEFT training. You will need a GPU for this. If you don’t have one, you can rent one from Vasti.ai.
Here’s an overview of the training code:
- Load the model – Load the base TinyLlama 1.1B Chat model from Hugging Face.
- Load the tokenizer – Load the tokenizer that matches the model and set the padding token to the end-of-sequence token.
- Configure quantization – Use 8-bit quantization (via BitsAndBytesConfig) to reduce memory usage and make training more efficient, especially on lower-spec hardware.
- Prepare for LoRA fine-tuning – Make the model ready for parameter-efficient fine-tuning by enabling LoRA and specifying which parts of the model to fine-tune (e.g. q_proj, v_proj).
- Load and format the dataset – Load the Alpaca-cleaned dataset from Hugging Face and use a sample subset (first 1,000 entries) for training. Format each training example in an instruction-following style with clear sections for instruction, input, and response.
- Tokenize the data – Convert the formatted text into token IDs that the model understands, and create matching labels for training.
- Set up trainer – Define hyperparameters such as batch size, learning rate, number of epochs, logging intervals, checkpoint saving, and use of half-precision (fp16). Set up the Hugging Face Trainer with the model, training data, tokenizer, and a data collator that handles padding and batching.
- Train the model – Run the training loop using the prepared dataset and LoRA-adapted model.
- Save the fine-tuned model – Save the final fine-tuned model and tokenizer locally for future use or inference.
And here’s the code:
from datasets import load_dataset
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling,
BitsAndBytesConfig
)
from peft import prepare_model_for_kbit_training, LoraConfig, get_peft_model
# === Load base model and tokenizer ===
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # Required for training
# Quantization config
bnb_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_threshold=6.0,
llm_int8_skip_modules=None
)
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
quantization_config=bnb_config
)
# === Prepare for LoRA fine-tuning ===
model = prepare_model_for_kbit_training(base_model)
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"], # Model-specific
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# === Load and format Alpaca dataset ===
dataset = load_dataset("yahma/alpaca-cleaned", split="train[:1000]")
def format_alpaca(example):
prompt = f"### Instruction:\n{example['instruction']}\n\n### Input:\n{example['input']}\n\n### Response:\n{example['output']}"
return {"text": prompt}
dataset = dataset.map(format_alpaca)
# === Tokenize dataset ===
def tokenize(example):
result = tokenizer(
example["text"],
truncation=True,
padding="max_length",
max_length=512
)
result["labels"] = result["input_ids"].copy()
return result
tokenized_dataset = dataset.map(tokenize, batched=True, remove_columns=dataset.column_names)
# === Set up Trainer ===
training_args = TrainingArguments(
output_dir="./tinyllama-lora",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
num_train_epochs=2,
logging_steps=10,
save_steps=100,
save_total_limit=1,
fp16=True, # Keep True for GPU
report_to="none"
)
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer,
data_collator=data_collator
)
# === Train the model ===
trainer.train()
# === Save fine-tuned model and tokenizer ===
model.save_pretrained("tinyllama-alpaca-lora")
tokenizer.save_pretrained("tinyllama-alpaca-lora")The key code for PEFT is this so it bears some explanation:
# === Prepare for LoRA fine-tuning ===
model = prepare_model_for_kbit_training(base_model)
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"], # Model-specific
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)prepare_model_for_kbit_training prepares the model for training with quantization.
LoraConfig set the parameters for LoRA:
- r=8 – This is the rank of the low-rank matrices inserted by LoRA. Think of it as the “capacity” of the adapter. A smaller r makes training faster and lighter, but may limit how much the adapters can learn.
- lora_alpha=16 – Controls how much influence the adapter layers have relative to the frozen original weights. A higher value increases the impact of LoRA updates, but can lead to instability if too high.
- target_modules – Specifies which layers inside the model should get LoRA adapters. This is model-specific in the case of TinyLlama it is q_proj and v_proj.
- lora_dropout=0.1 – Randomly drops a percentage of neurons during training to prevent overfitting by forcing the model to generalize better.
- bias=”none” – A bias term is added to the weighted sum in a neuron to help shift the activation function’s threshold, allowing more flexibility in learning. This parameter controls whether bias terms are to be trained. Options can also be “all” or “lora_only”, “none” is the default and keeps things lightweight.
- task_type – Specifies the type of task we’re fine-tuning for. “CAUSAL_LM” means causal language modeling, i.e., models that predict the next token in a sequence.
Finally, get_peft_model applies the LoRa to the model.
Inference With PEFT-Tuned Model
After training is done. We try inferencing with the PEFT-tuned model.
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
import torch
# Model name — make sure this matches what you used earlier
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
peft_model_path = "tinyllama-alpaca-lora" # Path to your LoRA fine-tuned adapter
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
# Choose device manually
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load base model on the selected device
base_model = AutoModelForCausalLM.from_pretrained(model_name)
base_model.to(device)
base_model.eval()
# Load PEFT model
model = PeftModel.from_pretrained(base_model, peft_model_path)
model.to(device)
model.eval()
# Generate function
def generate(model, prompt):
inputs = tokenizer(prompt, return_tensors="pt").to(device)
output = model.generate(**inputs, max_new_tokens=1024, do_sample=True, temperature=0.7)
return tokenizer.decode(output[0], skip_special_tokens=True)
# Alpaca-style instruction prompt
prompt = """### Instruction:
Explain the difference between renewable and non-renewable energy sources.
### Response:
"""
# Run AFTER fine-tuning
print("=== PEFT Fine-Tuned Response ===")
print(generate(model, prompt))The key code is PeftModel.from_pretrained which loads the base model and the PEFT model.
# Load PEFT model
model = PeftModel.from_pretrained(base_model, peft_model_path)
model.to(device)
model.eval()And that’s it. Thanks to HuggingFace, everything’s relatively straightforward.
The code is available in the GitHub repo as well as in the Google Colab Notebook.