
Retrieval Augmented Generation or RAG is a technique that enables generative artificial intelligence (Gen AI) models to retrieve and incorporate new information. It modifies interactions with a large language model (LLM) so that the model responds to user queries with reference to a specified set of documents, using this information to supplement information from its pre-existing training data. This allows LLMs to use domain-specific and/or updated information (Wikipedia) .
This is Part 3 of my series in LLM Customization. In this post, we will take a look at RAG. It is another fundamental LLM customization technique that is relatively simple, low-cost, and still requires no model modifications.
First we need to answer the question why we use RAG. Here are some reasons:
- Expands Knowledge – Many LLMs in popular use today are foundation models—pre-trained on general and publicly-available data to perform a wide range of tasks. They fall short in recent information, specialized domains, or when dealing with private data. RAG can expand the knowledge of the LLM with information from the web or a database.
- Enhances Accuracy – Related to 1, LLMs may hallucinate or generate or make up incorrect or misleading information when it lacks the required knowledge. By providing the additional knowledge, we enhance accuracy and reduce hallucinations.
- Optimizes Context Use – context refers to the input data (query, conversation history, user information, memory, knowledge, etc.) that the LLMs consider when generating a response. LLMs have a fixed “context window”, which defines how much text they can process at once. By including only relevant data, we optimize the use of this window.
- Better Reference and Source Attribution – once trained, many LLMs lose reference information. RAG can restore this information.
In this post, we will explore a simple (or naive) RAG implementation in Python.
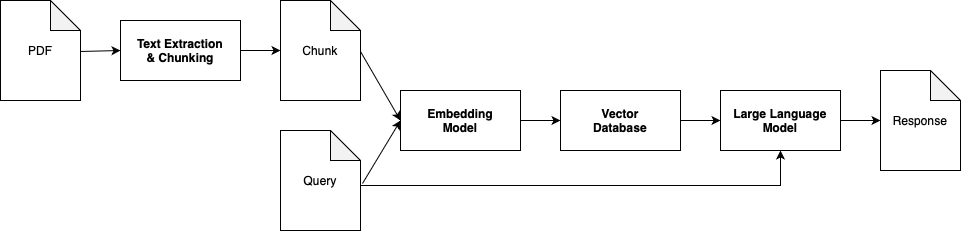
But first, some terminology:
- Vector – a mathematical entity that represents a direction and magnitude in a surface (2 dimensions) space (3 or more dimensions in our case)
- Embedding – are vector representations of data (text, images, audio, etc.) that capture their meaning, relationships, and semantic similarity in a multi-dimensional space. They allow computers to process and compare data based on meaning rather than just patterns.
- Embedding Model – is a type of machine learning model that converts data (text, images, audio, etc.) into embeddings.
- Vector Database – is a database that can store vectors optionally along with other data items. Vector databases typically implement one or more Approximate Nearest Neighbor algorithms, so that you can search the database with a query vector to retrieve the closest matching database records (Wikipedia).
We will create a legal reference application. We will start with creating the database. We will use a PDF as the knowledge source, in this case Republic Act 1123 aka the Revised Corporation Code.
The first step is chunking the document—splitting it into smaller segments of text. This allows us to avoid including the entire document in the limited context window of an LLM and instead focus only on the relevant parts. We’ll extract the text from the PDF using PyPDF2, and then split it into chunks using regular expressions. The splitting will follow the structure of the Corporation Code sections.
The second step is embedding. Embeddings allow us to capture the semantic meaning of each chunk and perform similarity-based retrieval. We’ll use the all-MiniLM-L6-v2 model from Sentence Transformers to generate embeddings for each chunk.
Once the embeddings are created, we’ll store them in a vector database—in this case, Facebook AI Similarity Search (FAISS). Since FAISS only stores vectors, we’ll save the corresponding text chunks separately using pickle for retrieval when a match is found.
Once the database has been created and indexed, we can now use our RAG. Given a query, we create an embedding for the query using the same embedding model we used to index our knowledge. We then do a semantic search in FAISS with the resulting embedding. The resulting indices are then used to retrieve the corresponding chunks. The chunks are then used to augment the prompt which is then input to the LLM along with the original query to generate a response. For the LLM we will be using gemini-1.5-pro-latest from Google.
First we install all the modules and libraries:
pip install faiss-cpu google-generativeai numpy pypdf2 python-dotenv sentence-transformers
Below is the code implementing this. It is also available in the GitHub repo.
import os
import pickle
import re
import faiss
import google.generativeai as genai
import numpy as np
import PyPDF2
from dotenv import load_dotenv
# Load env variables
load_dotenv()
GOOGLE_API_KEY = os.getenv("GOOGLE_API_KEY")
if not GOOGLE_API_KEY:
raise ValueError("Missing API key! Set GOOGLE_API_KEY in your .env file.")
genai.configure(api_key=GOOGLE_API_KEY)
# Load the PDF and extract text
def extract_text_from_pdf(pdf_path):
if not os.path.exists(pdf_path):
raise FileNotFoundError(f"PDF file not found: {pdf_path}")
text = ""
with open(pdf_path, "rb") as file:
reader = PyPDF2.PdfReader(file)
for page in reader.pages:
text += page.extract_text() + "\n"
return text
# Split the documents into chunks
def chunk_text(text):
# Split by sections (SEC. <section number>.)
chunks = re.findall(r'SEC\. \d+\..*?(?=SEC\. \d+\.|$)', text, re.DOTALL)
# Remove empty strings from the list
chunks = [chunk.strip() for chunk in chunks if chunk.strip()]
return chunks
# Generate embeddings and store in FAISS
def create_faiss_index(model_name, faiss_index_path, chunks_path, chunks):
embeddings = [
genai.embed_content(
model=model_name,
content=chunk,
task_type="retrieval_document"
)["embedding"]
for chunk in chunks
]
embeddings_array = np.array(embeddings, dtype=np.float32)
embedding_dim = embeddings_array.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings_array)
# Save FAISS index
faiss.write_index(index, faiss_index_path)
# Save chunks
with open(chunks_path, 'wb') as f:
pickle.dump(chunks, f)
return index
# Perform semantic search
def search_faiss(model_name, query, chunks, index, top_k=3):
query_embedding = genai.embed_content(
model=model_name,
content=query,
task_type="retrieval_query"
)["embedding"]
distances, indices = index.search(
np.array([query_embedding], dtype=np.float32),
top_k
)
return [chunks[i] for i in indices[0]]
# Generate response
def generate_response(model, query, context):
prompt = f"""You are a legal expert. Use the following context to answer the question. Do not hint that you're using context.
Context: {context}
Question: {query}"""
response = model.generate_content(prompt)
return response.text
# Main
pdf_path = "philippines-2019-legislation-ra-11232-revised-corporation-code-2019.pdf"
faiss_index_path = "faiss.index"
chunks_path = "faiss_index.pkl"
model_name = "models/text-embedding-004"
llm_name = "gemini-1.5-pro-latest"
# Load the vector store if it exists, otherwise create it
if os.path.exists(faiss_index_path) and os.path.exists(chunks_path):
print("Loading existing FAISS index...")
# Load the FAISS index
index = faiss.read_index(faiss_index_path)
# Load the chunks
with open(chunks_path, 'rb') as f:
chunks = pickle.load(f)
else:
print("Creating new FAISS index...")
# Extract text, chunk, and create the FAISS index
text = extract_text_from_pdf(pdf_path)
chunks = chunk_text(text)
index = create_faiss_index(model_name, faiss_index_path, chunks_path, chunks)
# LLM
llm = genai.GenerativeModel(llm_name)
# Interactive search
while True:
query = input("Ask a legal question (or type 'exit' to quit): ")
if query.lower() == 'exit':
break
try:
# 1. Retrieve
relevant_info = search_faiss(model_name, query, chunks, index)
# 2. Augment
context = "\n".join(relevant_info)
# 3. Generate
response = generate_response(llm, query, context)
print("\nGemini's Answer:")
print(response)
except Exception as e:
print(f"An error occurred: {e}")
To run it:
python rag.pyFor this first run, it will create and initialize the database. Succeeding runs, will not need this step. Once that’s done, you can start asking questions.
Creating new FAISS index...
Ask a legal question (or type 'exit' to quit): when do we need to conduct election of officers?We now have a basic RAG application. From this foundation, we can evolve towards more advanced implementations by integrating multi-modal support, refining pre-processing and retrieval techniques, and optimizing LLM interactions. In many cases, a well-designed RAG system, combined with effective prompt engineering, can be sufficient to meet your needs.