
Artificial intelligence or AI is all the rage these days, driving amazing innovations across multiple industries and transforming how we interact with technology. Machine learning, a subset of AI, plays a crucial role in this transformation by enabling systems to learn from data and improve over time. Among the most powerful techniques in machine learning are Artificial Neural Networks (ANNs), which are modeled after the human brain and have become essential for solving complex problems in fields like image recognition, voice recognition, natural language processing, and predictive analytics. In this post, we will explore the basics of ANNs and how they work.
Artificial Neural Networks
An artificial neural network is a machine learning model inspired by the structure and function of the human brain. The power of neural networks lies in their ability to automatically learn hierarchical representations of data. Unlike traditional algorithms, neural networks can identify complex patterns and relationships in data without explicit programming. They achieve this through layers of interconnected neurons, enabling them to learn and handle complex tasks where manual feature extraction and processing is difficult or impossible. Their adaptability makes them particularly powerful for tasks that would otherwise require complex mental processing– or, in short, intelligence.
The Human Brain

The human brain is the central organ in the nervous system, responsible for processing and integrating information. It is a complex organ composed of multiple regions such as the frontal lobe, parietal lobe, temporal lobe, occipital lobe, cerebellum, thalamus, hypothalamus, and brainstem, among others. All of these regions contain neural circuits, which are made up of neurons.
Neurons
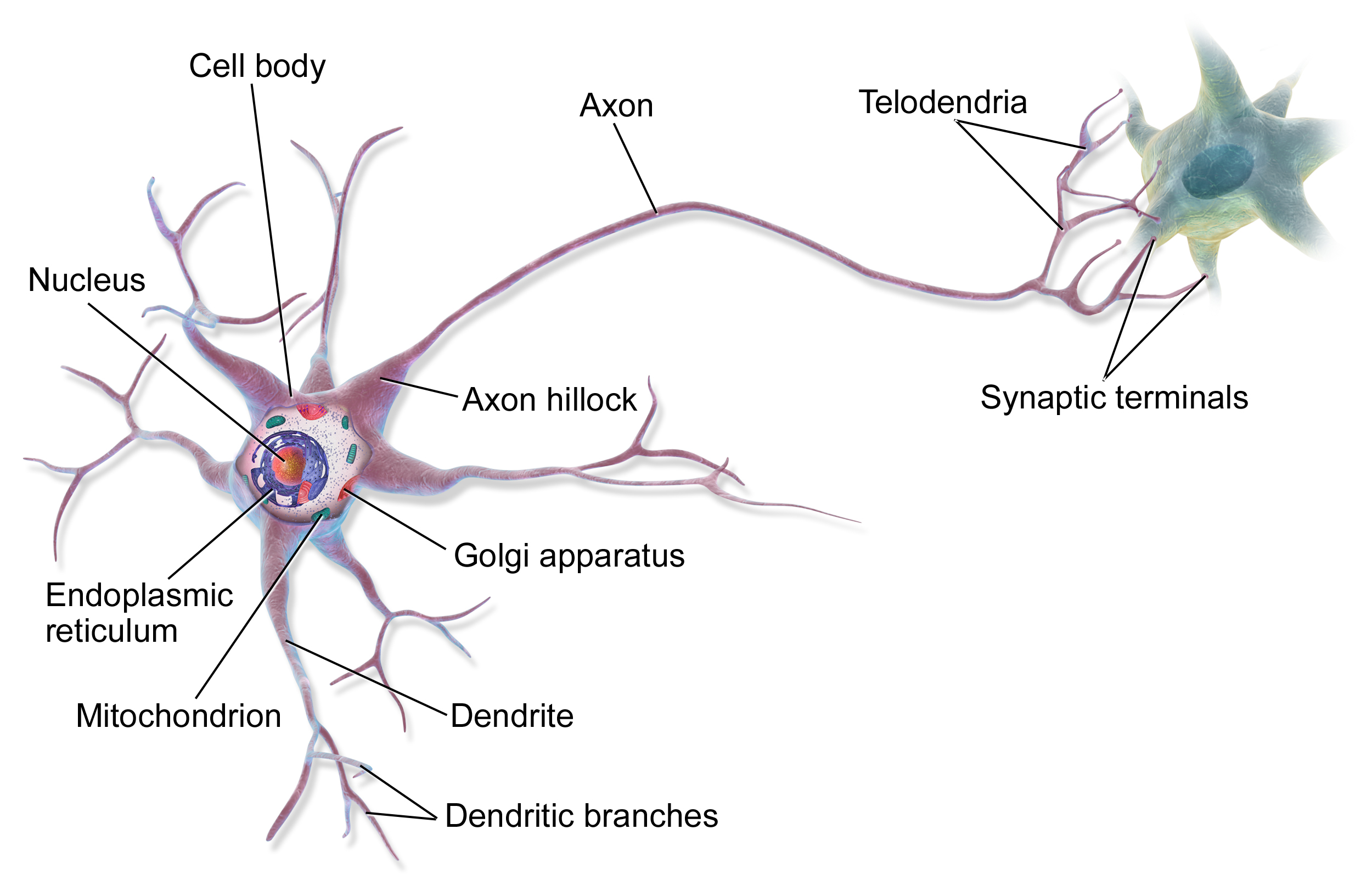
Neurons are a type of cell that receive and transmit messages between the body and the brain. These messages are sent across chains of neurons through weak electrical impulses called action potentials and chemicals known as neurotransmitters. The key components of a neuron are the soma, dendrites, axon, and synapses:
- Soma: The cell body of a neuron, containing the nucleus and responsible for metabolic activities and processing information.
- Dendrites: Branch-like structures that receive signals from other neurons and transmit them to the soma.
- Axon: A long, cable-like structure that transmits electrical impulses away from the soma to other neurons or target cells.
- Synapses: Junctions between two neurons where neurotransmitters are released, allowing communication between neurons.
The neuron is the basis for artificial neurons.
Artificial Neurons
Artificial neurons are inspired by its biological counterpart but is [vastly] simplified into a mathematical model. The key components of an artificial neuron include:
- Inputs: The neuron receives several inputs, each associated with a weight that represents the importance or strength of that input. This is analogous to dendrites.
- Weighted Sum: The inputs are multiplied by their corresponding weights, and then summed together. This sum is the raw input to the neuron.
- Bias: A bias term is added to the weighted sum to help shift the activation function’s threshold, allowing more flexibility in learning.
- Activation Function: The raw sum is passed through an activation function, which introduces non-linearity into the network, enabling it to model complex patterns.
- Output: The result of the activation function is the output of the neuron, which can either be used as input to another neuron or as a final output in the case of the network’s last layer. This is analogous to axons.
Mathematically, the output of a single artificial neuron can be written as:
\( y = f\left( \sum_{i=1}^{n} w_i x_i + b \right) \)where:
\(\begin{array}{l}
y \text{ is the output,} \\
x_1, x_2, \dots, x_n \text{ are the inputs,} \\
w_1, w_2, \dots, w_n \text{ are the weights,} \\
b \text{ is the bias,} \\
f \text{ is the activation function.}
\end{array}
\)
This mathematical model is implemented in code and interconnected via data structures to form a neural network.
Neural Networks

A neural network consists of multiple logical layers of neurons that work together to process and interpret data. These layers are typically structured as follows:
- Input Layer: The first layer that receives the raw input data.
- Hidden Layers: These layers process the inputs by transforming them through weighted sums and activation functions. Multiple hidden layers allow the network to learn increasingly complex features.
- Output Layer: The final layer, which produces the prediction or classification based on the processed features.
Each layer in a neural network receives input from the previous layer, performs a transformation, and passes the result to the next layer. The complete structure is the neural network or model.
Training and Evaluation
The power of neural networks comes from their ability to learn hierarchical representations of data. To do this, they need to be trained with large amounts of data, called datasets. Typically, the dataset is partitioned into training and testing data.
The training data is used to train the model. It is processed in runs called an epochs. First, the data is fed into the model in a process called forward pass where the model makes predictions, computes errors using a loss function, and then minimizes the error by adjusting the weights through a process called backward pass or back propagation.
The test data is used to evaluate the performance of the model. Two important metrics derived from evaluation are loss and accuracy. Loss measures how far the model’s predictions are from the actual (expected) values, giving an indication of the model’s error. Accuracy reflects the proportion of correct predictions out of the total predictions.
Training typically involves multiple epochs to allow the model to gradually converge to a state with acceptable performance. After initial evaluation, further adjustments and modifications to the model architecture or parameters as well as re-training may be required to achieve the desired results.
Inference
Once the network reaches an acceptable state, it can be used for inference. Inference in machine learning refers to the process of using a trained model to make predictions or decisions based on new, unseen data. The input data is pre-processed to match the format and characteristics of the training data. This often involves tasks like image processing, audio processing, or other data preparation techniques. The data is then fed into the model for tasks such as classification, prediction, recognition, or decision-making. Ideally, the model will produce the desired result.
Conclusion
And that concludes this short introduction to ANNs. We have barely scratched the surface but it should be sufficient to proceed further in our exploration of AI. For deeper and more detailed information, I recommend reading Neural Networks and Deep Learning by Michael Nielsen and watching the Neural Network video series by 3Blue1Brown. In the next post, I will look at implementing an ANN.